Election Audits is a modern web app for auditing elections to help election officials use risk-limiting audits using ballot-polling, ballot-comparison, canvass, and Bayesian ballot-polling audits; each supporting multiple winners/“vote for n”. Also includes a sample-size demo page, comparing the risk limit of ballot-polling and ballot-comparison audits are arbitrary risk limits using real election data from openelections.net.
My group was tasked with creating a user-friendly and “less-Javascripty” version of Dr. Philip Stark’s Tools for Ballot-Polling Risk-Limiting Election Audits and Tools for Comparison Risk-Limiting Election Audits to guide real election officials through the auditing process. (We added three additional audit methods on top of the two Dr. Stark’s website supports.) Especially with more and more states piloting risk-limiting audits, officials are in need of tools to help them conduct audits that don’t require advanced statistical knowledge. In our app, users need only fill out basic data regarding the ballot data and follow step-by-step instructions to conduct an audit. Though most elections would have their audit methods determined by legislation, the home page describes differences between the methods we implemented and potential use-cases.
The app was implemented with a Python server and audit methods with a static frontend. The frontend communicates with the server using sockets, and the backend delegates requests to the appropriate audit method and returns responses to guide the user through the audit process. The implementations of audit methods are Python translations of the pseudocode provided in the relevant literature. 1 2 3 4 5
As part of this project, I submitted changes to Ron Rivest’s 2018-bptool project, in order to let BayesianPolling.py be a wrapper around his code with the same interface as the other audit methods.
While the project was once live on election-audits.org, it was taken down after the conclusion of the class due to hosting costs. However, it can still be used by election officials through local installations!
Screenshots
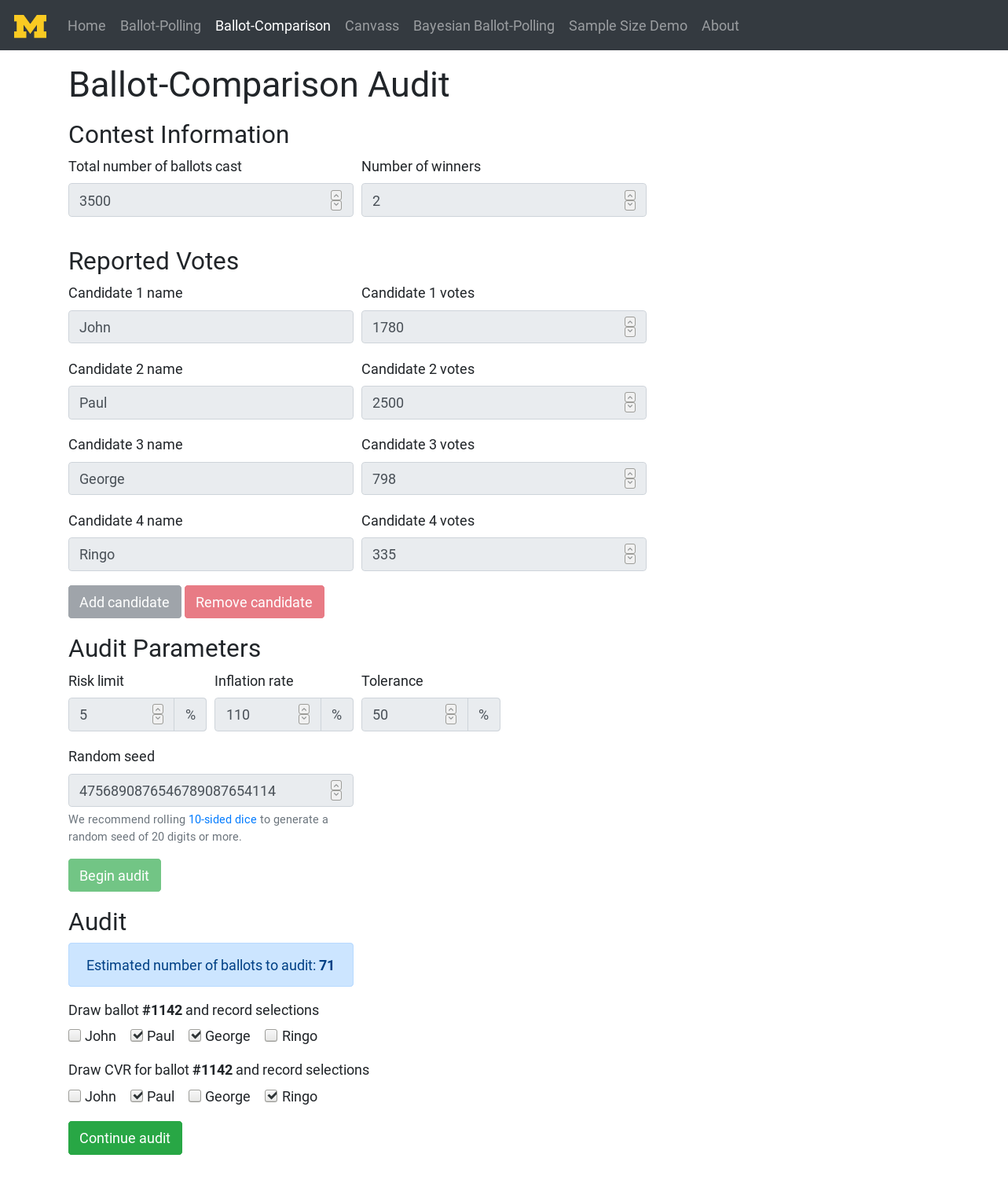
The ballot-comparison method takes in reported election data and has the user draw paper ballots at random to compare the actual vote with the computer-recorded vote. This method is highly efficient; notice how few ballots need be drawn to confirm the reported election result.
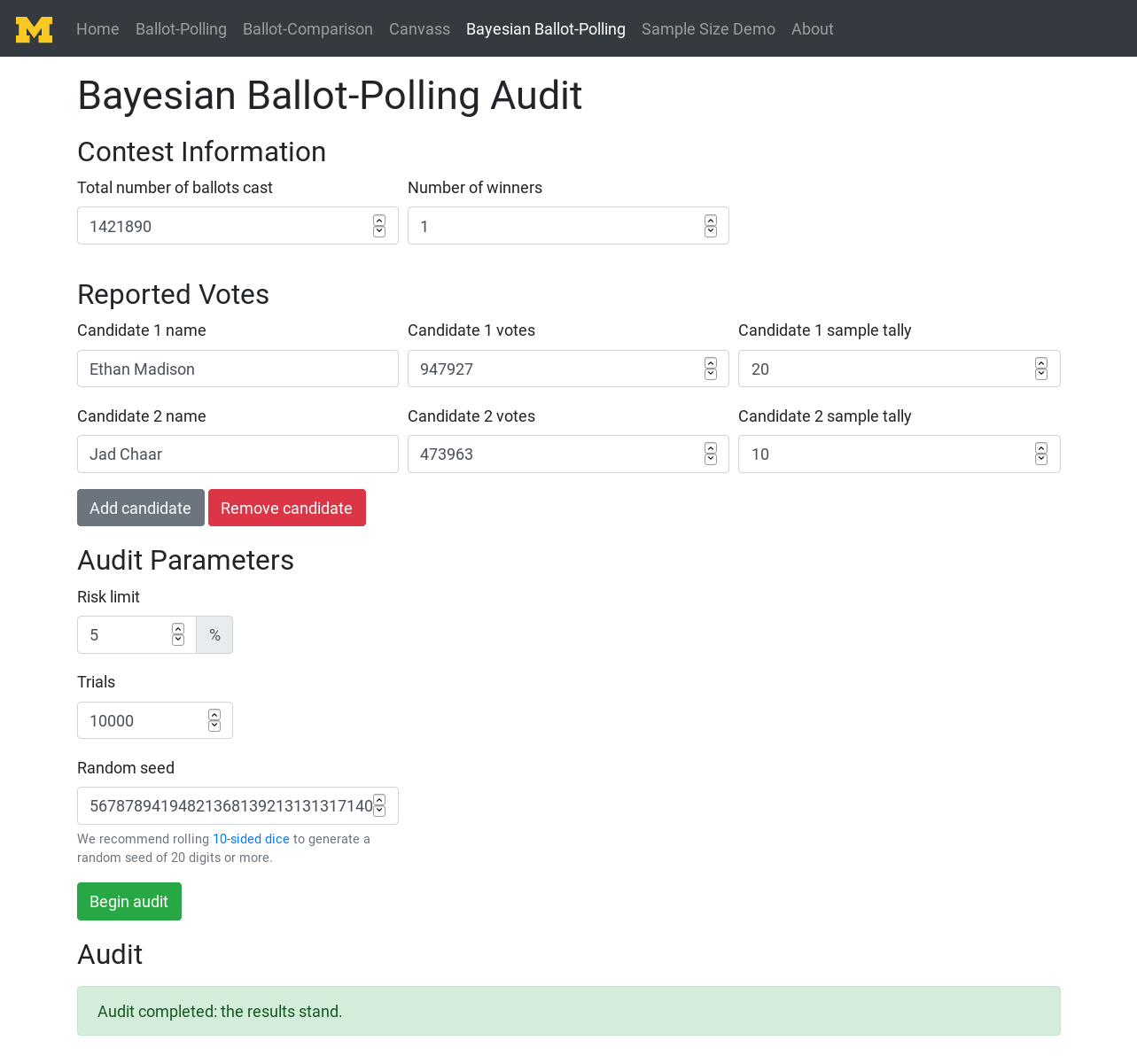
Bayesian audit methods are different from other risk-limiting audits in that the work is front-loaded: the user first checks some ballots then asks the tool if this auditing is enough to confirm the election results.
Source Code
All source for the project is available on Github.
Samples
Below are a few of the more interesting functions from Bravo.py (the ballot-comparison method we implemented), which do most of the audit method’s work.
def get_margins(self):
"""
Return an array `margins`, for which for each winner and loser,
margins[winner][loser] ≡ votes_array[winner]/(votes_array[winner]
+ votes_array[loser]),
is the fraction of votes `winner` was reported to have received among
ballots reported to show a vote for `winner` or `loser` or both.
"""
margins = np.zeros([self.num_candidates, self.num_candidates])
for winner in self.candidates.winners:
for loser in self.candidates.losers:
margins[winner][loser] = self.votes_array[winner] \
/ (self.votes_array[winner] + self.votes_array[loser])
return margins
def get_ballot(self):
""" Step 2 of the BRAVO algorithm.
Randomly picks a ballot to test and returns a list of its votes.
The ballot picked is returned to the frontend for the user to input
actual votes on the ballot. The ballot should be selected using a
random function seeded by a user-generated seed.
Note: 'random' should be seeded before this function is called.
"""
ballot_votes = self.get_votes()
if len(ballot_votes) > self.num_winners:
return []
return ballot_votes
def update_hypothesis(self, winner, loser):
""" Step 5 of the BRAVO algorithm.
Rejects the null hypothesis corresponding to the test statistic of
the `winner` and `loser` pair. Increments the null hypothesis
rejection count.
"""
if self.hypotheses.test_stat[winner][loser] >= 1/self.risk_limit:
self.hypotheses.test_stat[winner][loser] = 0
self.hypotheses.reject_count += 1
def update_audit_stats(self, vote):
""" Steps 3-5 from the BRAVO algorithm.
Updates the `test_statistic` and rejects the corresponding null
hypothesis when appropriate.
"""
if vote in self.candidates.winners: # Step 3
for loser in self.candidates.losers:
self.hypotheses.test_stat[vote][loser] \
*= 2*self.margins[vote][loser]
self.update_hypothesis(vote, loser)
elif vote in self.candidates.losers: # Step 4
for winner in self.candidates.winners:
self.hypotheses.test_stat[winner][vote] \
*= 2*(1-self.margins[winner][vote])
self.update_hypothesis(winner, vote)
“A gentle introduction to risk-limiting audits” (Lindeman and Stark 2012). ↩︎
“BRAVO: ballot-polling risk-limiting audits to verify outcomes” (Lindeman, Stark, and Yates 2012). ↩︎
“Canvass audits by sampling and testing” (Stark 2009). ↩︎
“Super-simple simultaneous single-ballot risk-limiting audits” (Stark 2010). ↩︎
“Bayesian Tabulation Audits: Explained and Extended” (Rivest 2018). ↩︎